





Ce qui inquiète les spécialistes de la protection de la vie privée
Trois étudiants diplômés de Stanford ont développé un projet appelé Predicting Image Geolocations (PIGEON), une intelligence artificielle (IA) capable de géolocaliser avec précision des photos, même celles qui n’ont jamais été vues par le programme auparavant. Initialement conçu pour identifier des lieux sur Google Street View, PIGEON peut maintenant deviner l’emplacement d’une image Google Street View n’importe où sur terre avec une précision élevée.
La géolocalisation d’images à l’échelle de la planète reste un problème difficile en raison de la diversité des images provenant de n’importe où dans le monde. Bien que les approches basées sur les transformateurs de vision aient fait des progrès significatifs dans la précision de la géolocalisation, le succès de la littérature antérieure est limité à des distributions étroites d’images de points de repère, et la performance n’a pas été généralisée à des lieux non vus.
Bien que la technologie PIGEON puisse avoir des applications bénéfiques, comme aider à identifier des endroits sur des photos anciennes ou faciliter les enquêtes biologiques sur la biodiversité, elle suscite également des préoccupations en matière de vie privée. Des experts craignent que cette capacité puisse être utilisée à des fins de surveillance gouvernementale, de suivi des entreprises ou de harcèlement. Malgré ses avantages potentiels, l’efficacité de PIGEON soulève des questions sur la protection de la vie privée et son utilisation future.
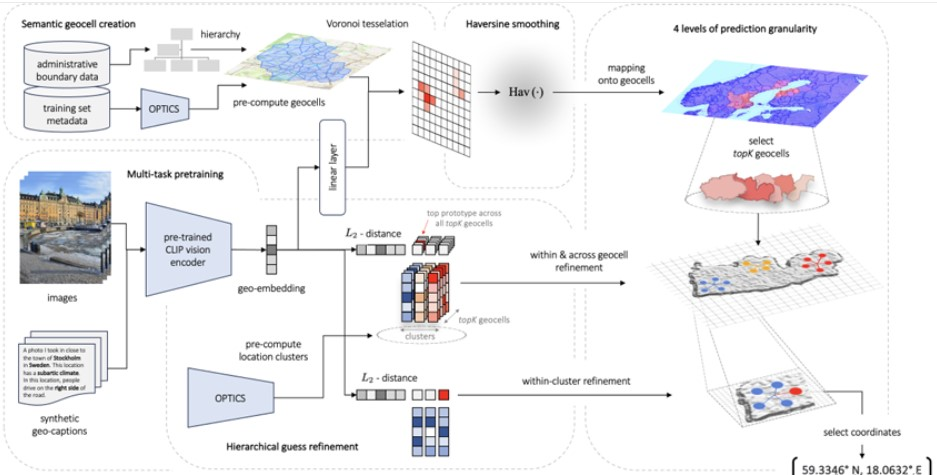
Les chercheurs de l’Université de Stanford ont introduit un nouveau système de géolocalisation qui intègre la création de géocellules sémantiques, le pré-entraînement contrastif multitâche et une fonction de perte innovante. Leur travail constitue la première tentative d’exploration de groupes de lieux pour affiner les estimations. Le premier modèle, baptisé PIGEON, a été formé sur les données du jeu Geoguessr, démontrant une capacité à placer plus de 40 % de ses estimations à moins de 25 kilomètres de la cible à l’échelle mondiale. Les chercheurs ont également mis au point un bot et ont soumis PIGEON à une expérience en aveugle contre des joueurs humains, se classant parmi les 0,01 % des meilleurs joueurs.
Dans une série de six matchs diffusés devant des millions de téléspectateurs, ils ont défié l’un des plus grands joueurs professionnels de Geoguessr et ont remporté tous les matchs. Leur deuxième modèle, PIGEOTTO, se distingue par son entraînement sur un ensemble de données d’images provenant de Flickr et de Wikipedia. Il a surpassé l’ancien modèle SOTA de 7,7 points de pourcentage en termes de précision des villes et de 38,8 points de pourcentage au niveau des pays, démontrant des performances exceptionnelles sur divers critères de référence en matière de géolocalisation d’images. Les résultats suggèrent que PIGEOTTO est le premier modèle de géolocalisation d’images capable de généraliser efficacement à des lieux non vus, ouvrant ainsi la voie à des systèmes de géolocalisation d’images très précis à l’échelle mondiale.
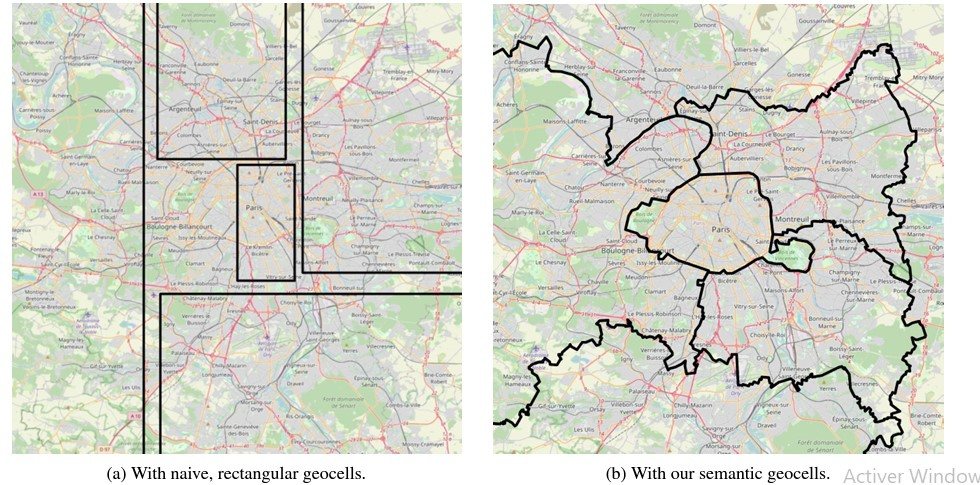
Les données administratives et les informations sur les formations sont structurées de manière hiérarchique, regroupées et subdivisées en cellules géographiques sémantiques à l’aide de la méthode de Voronoï. Les étiquettes des cellules géographiques sont ensuite utilisées pour créer des étiquettes continues sans lissage des transitions. Les modèles interprétatifs CLIP et de regroupement OPTICS sont exploités pour générer des représentations des regroupements d’emplacements.
Pendant la phase d’inférence, la densité de l’image animée est calculée et initialement transmise à une couche linéaire pour produire des prédictions de cellules géométriques, identifiant ainsi les candidats aux cellules géométriques supérieures. Cette densité est ensuite intégrée dans notre processus d’affinage pour améliorer les prédictions au sein et entre les cellules géométriques, en minimisant la distance L2 entre la densité de l’image d’inférence et les représentations des amas de localisation par rapport aux cellules géométriques supérieures. Enfin, les prédictions sont raffinées au sein du regroupement supérieur identifié afin de générer des coordonnées géographiques en sortie.
Définition du problème de géolocalisation d’images
La localisation d’images pose le défi de mettre en correspondance des images animées avec des coordonnées permettant d’identifier leur lieu de capture. La complexité du problème réside non seulement dans sa formulation globale, mais aussi dans la difficulté à réaliser une localisation précise en raison des variations de jour, de temps, de saison, d’heure, d’éclairage, de climat, de circulation, d’angle de vue, et d’autres facteurs.
La première tentative moderne de localisation d’images à l’échelle mondiale remonte à IM2GPS (2008) (Hays & Efros, 2008), une approche basée sur la recherche de caractéristiques créées manuellement. Toutefois, la dépendance envers les méthodes de recherche du plus proche voisin (Zamir & Shah, 2014) utilisant des caractéristiques visuelles créées manuellement (Crandall et al., 2009) implique la nécessité d’une vaste base de données d’images de référence, rendant la localisation géographique précise à l’échelle mondiale pratiquement impossible. Par conséquent, les travaux ultérieurs ont opté pour une approche plus restreinte en se concentrant sur des villes spécifiques telles qu’Orlando et Pittsburgh (Zamir & Shah, 2010) ou San Francisco (Berton et al., 2022).
Certains ont choisi de cibler des pays spécifiques pour des considérations de sécurité et de confidentialité, comme les États-Unis, ou même des caractéristiques géographiques plus spécifiques telles que des chaînes de montagnes, des déserts et des plages.
Géolocalisation hiérarchique d’images avec des étiquettes basées sur le lissage de distance : En abordant la discrétisation du problème de géolocalisation d’images, nous créons un compromis entre la granularité des géocellules et la précision des prédictions. Bien que des géocellules plus fines permettent des prédictions plus précises, elles rendent la classification plus complexe en raison d’une cardinalité plus élevée. La littérature antérieure a traité ce défi en produisant des prédictions de géolocalisation distinctes à plusieurs niveaux de granularité géographique, affinant les estimations à chaque niveau subséquent ; présentent également des architectures qui partagent certains paramètres de modèle entre différents niveaux hiérarchiques, améliorant ainsi les performances de géolocalisation.
Cependant, toutes ces approches antérieures partagent une limitation commune : les modèles fonctionnent de manière isolée, ignorant quelles géocellules sont adjacentes les unes aux autres. L’approche surmonte cette limitation significative en partageant tous les paramètres entre plusieurs niveaux implicites de hiérarchies géographiques. Cela est réalisé grâce à une fonction de perte qui connecte les géocellules adjacentes en ajustant l’étiquetage en fonction de la distance haversine. Cette dernière mesure la distance entre deux points à la surface de la Terre. Pour deux points donnés, p1=(λ1,ϕ1) et p2=(λ2,ϕ2), de longitude λ et de latitude ϕ, la distance haversine Hav(p1,p2) est calculée en kilomètres comme suit :
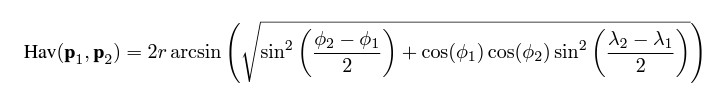
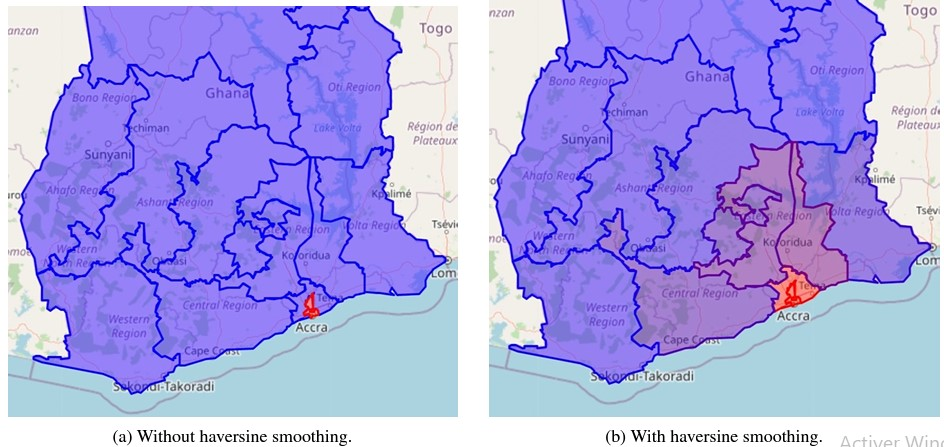
Nous « lissons » ensuite l’étiquette de classification géocellulaire originale à un coup à l’aide de cette métrique de distance selon l’équation suivante pour un échantillon n et un géocelli donnés :
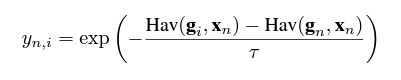
où gi sont les coordonnées du centroïde du polygone de la cellule i, gn sont les coordonnées du centroïde de la vraie cellule, xn sont les vraies coordonnées de l’exemple pour lequel l’étiquette est calculée, et τ est un paramètre de température qui est fixé à 75 pour PIGEON et à 65 pour PIGEOTTO dans nos expériences. Il est important de noter que notre “haversinesmoothing” est différent du “labelsmoothing” classique car les étiquettes ne sont pas décomposées en utilisant un facteur constant mais en se basant à la fois sur la distance par rapport à la géocellule correcte et à la localisation réelle.
Étant donné que pour chaque exemple d’apprentissage, plusieurs géocellules auront une cible yn, i significativement plus grande que zéro, notre modèle apprend simultanément à prédire la bonne géocellule ainsi qu’un niveau de granularité géographique encore plus grossier. Nous concevons la fonction de perte suivante basée sur le lissage haversine pour un échantillon d’apprentissage particulier :
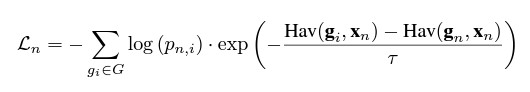
où pn, i représente la probabilité que notre modèle assigne à la géocellule i pour l’échantillon n. Un avantage supplémentaire de l’utilisation de la perte définie par l’équation précédente réside dans son impact positif sur la généralisation, car les définitions de la hiérarchie varient à travers chaque échantillon d’apprentissage. De plus, en cas où un échantillon se situe à proximité de la frontière entre deux géocellules, cette réalité se reflétera par des étiquettes cibles approximativement égales pour l’ensemble des géocellules.
Ceci s’avère particulièrement utile pour les grandes géocellules, comprenant jusqu’à dix cellules rurales. Par ailleurs, étant donné que chaque étiquette cible yn, i est désormais continue et que la complexité du problème de classification peut être librement ajustée à l’aide de τ, un nombre arbitraire de géocellules peut être utilisé, à condition que ces géocellules restent significatives du point de vue contextuel et contiennent un nombre minimum d’échantillons.
Enfin, il est à noter que notre perte de classification repose désormais directement sur la distance par rapport à la localisation réelle xn d’un échantillon donné, en contournant ainsi les difficultés liées à la régression rencontrées dans la littérature antérieure.
Les trois étudiants diplômés de Stanford ont introduit une nouvelle approche multi-tâches pour la localisation d’images à l’échelle mondiale, garantissant des performances de pointe tout en démontrant une robustesse face aux variations de distribution. Afin de valider l’efficacité de l’approche, ils forment et évaluent deux modèles distincts de localisation d’images. Initialement, nous collectons des données mondiales provenant de StreetView pour entraîner PIGEON, un modèle multi-tâches qui se classe parmi les 0,01 % des joueurs humains dans le jeu Geoguessr.
Sur un ensemble de données comprenant 5 000 emplacements de StreetView, PIGEON utilise efficacement 40,4 % de l’espace de jeu pour la localisation d’images. Par la suite, nous assemblons un ensemble de données mondial de plus de 4 millions d’images tirées de Flickr et de Wikipedia pour former le modèle général PIGEOTTO, améliorant ainsi la qualité des résultats sur une gamme plus étendue d’ensembles de données de géolocalisation de manière significative.
Concernant l’avenir, la question demeure de savoir si les technologies de géolocalisation d’images adopteront une véritable portée mondiale ou se concentreront sur des distributions spécifiques de la population. Quoi qu’il en soit, les conclusions sur l’importance de la création sémantique de cellules géométriques, de la formation multimodale à l’interprétation contrastive, et du raffinement précis des cellules géométriques, entre autres, mettent en lumière des éléments fondamentaux cruciaux pour de tels systèmes.
Néanmoins, le déploiement ultérieur de la technologie de localisation d’images devra équilibrer les avantages potentiels avec les risques éventuels, assurant ainsi un développement judicieux des futurs systèmes de surveillance informatique.
La conclusion des travaux des chercheurs présente un panorama positif des travaux des étudiants diplômés de Stanford sur la géolocalisation d’images à l’échelle mondiale. Cependant, quelques points méritent une réflexion critique.
Analyse critique de l’approche des étudiants de Stanford en géolocalisation d’images
Tout d’abord, la déclaration selon laquelle leur approche garantit des performances de pointe et une robustesse face aux variations de distribution peut nécessiter des détails supplémentaires et des preuves concrètes pour étayer cette affirmation. Des comparaisons avec d’autres approches existantes ou des explications sur la manière dont leur modèle surmonte spécifiquement les défis liés à la distribution seraient bénéfiques.
En ce qui concerne les résultats spécifiques des modèles PIGEON et PIGEOTTO, bien que le pourcentage de l’espace de jeu utilisé pour la localisation d’images soit mentionné, une évaluation plus approfondie des performances, des métriques de précision et de rappel, ainsi que des comparaisons avec d’autres modèles existants, pourrait renforcer la crédibilité de leurs résultats.
Par ailleurs, la question soulevée quant à savoir si les technologies de géolocalisation d’images seront mondiales ou axées sur des distributions spécifiques est pertinente, mais elle mériterait une exploration plus approfondie. Des réflexions sur les implications éthiques, sociales et politiques de telles technologies seraient également un ajout valable à la discussion.
Bien que la conclusion souligne des éléments fondamentaux cruciaux pour les systèmes de géolocalisation d’images, une approche plus nuancée, des données comparatives plus détaillées et une exploration approfondie des implications futures de cette technologie pourraient renforcer la qualité et la robustesse du travail des étudiants de Stanford.
source : developpez