





GitHub considère qu’il s’agit d’une fonctionnalité et non d’un bogue
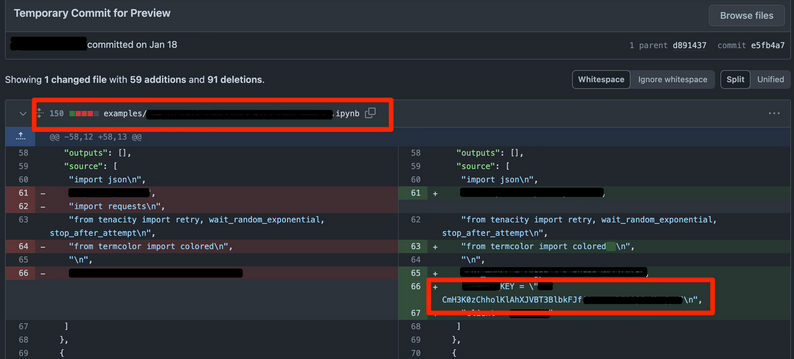
Sur GitHub, il est possible d’accéder aux données de dépôts supprimés, de forks supprimés et même de dépôts privés. Cette vulnérabilité, connue sous le nom de Cross Fork Object Reference (CFOR), est intentionnellement conçue par GitHub et représente un vecteur d’attaque majeur pour les organisations utilisant cette plateforme.
Les chercheurs de Truffle Security ont découvert, ou plutôt redécouvert, que les données des dépôts GitHub supprimés (publics ou privés) et des copies supprimées (forks) des dépôts ne sont pas nécessairement supprimées.
Joe Leon, un chercheur en sécurité de l’organisation, a déclaré dans un avis publié mercredi que la possibilité d’accéder aux données supprimées d’un dépôt – telles que les clés d’API – représente un risque pour la sécurité. Il a proposé un nouveau terme pour décrire cette vulnérabilité présumée : Cross Fork Object Reference (CFOR).
Leon explique : « Une vulnérabilité CFOR se produit lorsqu’une fork du référentiel peut accéder à des données sensibles d’un autre fork (y compris des données de fork privées et supprimées). Comme dans le cas d’une référence directe à un objet (Insecure Direct Object Reference), dans le cas d’une vulnérabilité CFOR, les utilisateurs fournissent des hachages de livraisons pour accéder directement à des données de livraisons qui, autrement, ne leur seraient pas visibles ».
Accès aux données de forks supprimés
Imaginons que vous ayez forké un dépôt public, y ayez ajouté du code, puis supprimé votre fork. Logiquement, ce code ne devrait plus être accessible. Pourtant, il l’est, et ce de manière permanente.
Dans la vidéo ci-dessous, vous verrez Truffle Security forker un dépôt, y livrer des données, supprimer le fork, puis accéder aux données « supprimées » via le dépôt d’origine.
Vous pourriez penser que vous êtes protégé en ayant besoin de connaître le hash du commit. Ce n’est pas le cas. Le hash peut être découvert. Nous y reviendrons plus tard.
À quelle fréquence peut-on trouver des données provenant de forks supprimées ?
Assez souvent. Truffle Security indique avoir étudié quelques (littéralement 3) dépôts publics couramment forkés d’une grande entreprise d’IA et avoir facilement trouvé 40 clés d’API valides provenant de forks supprimés. Le schéma de l’utilisateur semble être le suivant :
- 1. Forcer le dépôt.
- 2. Coder en dur une clé API dans un fichier d’exemple.
- 3. <Faire le travail>
- 4. Supprimer le fork.
Mais le pire, c’est que cela fonctionne aussi en sens inverse :
Accès à des données repo supprimées
Considérons le scénario suivant :
- – Vous avez un dépôt public sur GitHub.
- – Un utilisateur fork votre repo.
- – Vous livrez des données après qu’il l’ait forké (et il ne synchronise jamais son fork avec vos mises à jour).
- – Vous supprimez l’ensemble du repo.
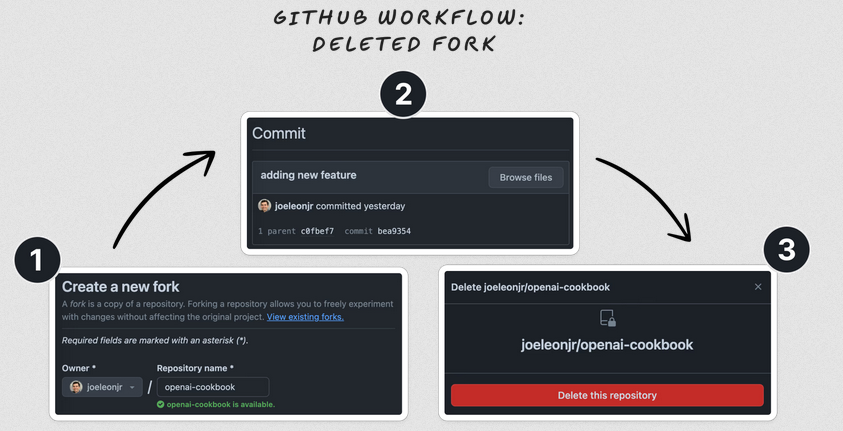
Le code que vous avez livré après qu’ils aient forké votre repo est-il toujours accessible ?
Oui.
GitHub stocke les dépôts et les forks dans un réseau de dépôts, le dépôt original « en amont » jouant le rôle de nœud racine. Lorsqu’un dépôt public « en amont » ayant fait l’objet d’un fork est « supprimé », GitHub réattribue le rôle de nœud racine à l’un des forks en aval. Cependant, tous les commits du dépôt « en amont » existent toujours et sont accessibles via n’importe quel fork.
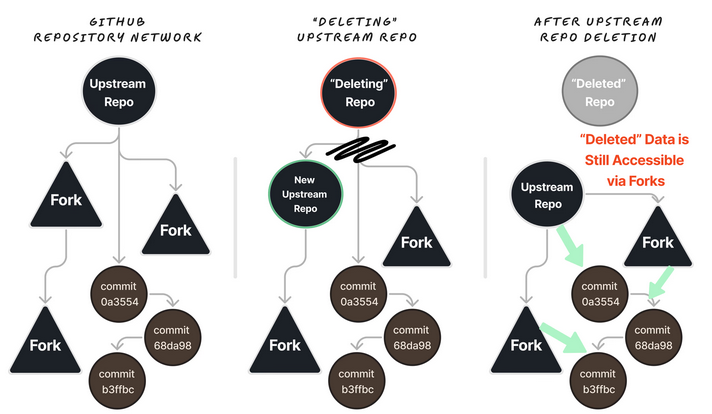
Dans la vidéo ci-dessous, Truffle Security a créé un repo, l’a forké et a montré ensuite comment les données qui ne sont pas synchronisées avec le fork peuvent encore être accédées par le fork après la suppression du repo original.
Il ne s’agit pas d’un scénario bizarre. Il s’est déroulé la semaine dernière :
« J’ai soumis une vulnérabilité P1 à une grande entreprise technologique qui a accidentellement livré une clé privée pour le compte GitHub d’un employé qui avait un accès important à l’ensemble de leur organisation GitHub. Ils ont immédiatement supprimé le dépôt, mais comme il avait été forké, je pouvais toujours accéder au commit contenant les données sensibles via un fork, bien que le fork n’ait jamais été synchronisé avec le dépôt original “en amont” ».
L’implication ici est que tout code engagé dans un dépôt public peut être accessible pour toujours tant qu’il existe au moins un fork de ce dépôt.
Et ce n’est pas tout.
Accès aux données de repo privées
Considérez ce flux de travail commun pour l’open-sourcing d’un nouvel outil sur GitHub :
- – Vous créez un repo privé qui sera éventuellement rendu public.
- – Vous créez une version interne privée de ce dépôt (via un fork) et vous livrez du code supplémentaire pour les fonctionnalités que vous n’allez pas rendre publiques.
- – Vous rendez public votre dépôt « en amont » et gardez votre fork privé.
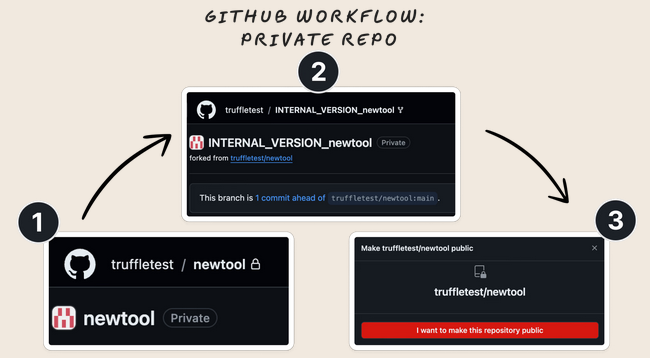
Vos fonctionnalités privées et le code correspondant (de l’étape 2) sont-ils visibles par le public ?
Oui. Tout code modifié entre le moment où vous avez créé une version interne de votre outil et le moment où vous avez ouvert l’outil à la concurrence est accessible sur le dépôt public.
Les modifications apportées à votre fork privé après que vous ayez rendu public le dépôt « amont » ne sont pas visibles. En effet, la modification de la visibilité d’un dépôt privé « en amont » entraîne la création de deux réseaux de dépôts – un pour la version privée et un pour la version publique.
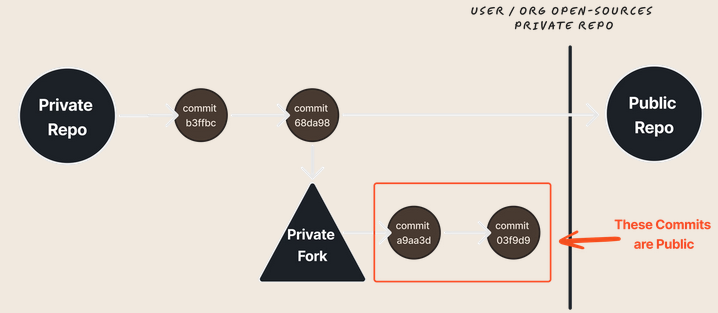
Dans la vidéo ci-dessous, Truffle Security montre comment les organisations mettent de nouveaux outils en open source tout en conservant des forks internes privées, puis comment quelqu’un peut accéder aux données de validation de la version interne privée par le biais de la version publique.
Malheureusement, ce flux de travail est l’une des approches les plus courantes que les utilisateurs et les organisations adoptent pour développer des logiciels libres. Par conséquent, il est possible que des données confidentielles et des secrets soient exposés par inadvertance sur les dépôts publics GitHub d’une organisation.
Vous pouvez forker
Il s’agit clairement d’un problème. Mais ce n’est pas un problème au point que GitHub considère CFOR comme une vulnérabilité légitime. En fait, le géant de l’hébergement de code, propriété de Microsoft, considère qu’il s’agit d’une fonctionnalité et non d’un bogue. Informé de la situation par le biais de son programme de divulgation des vulnérabilités, GitHub a répondu : « Il s’agit d’une décision de conception intentionnelle et elle fonctionne comme prévu, comme indiqué dans notre [documentation]. »
Il est évident que cela est connu depuis des années. Une personne affirme avoir notifié GitHub de la vulnérabilité en 2018 et avoir reçu une réponse similaire.
Lors d’un entretien, Dylan Ayrey, cofondateur et PDG de Truffle Security, a expliqué que le problème se résumait à ce que l’on appelle un dangling commit.
Un « dangling commit » est une primitive git, explique Ayrey. « Ce n’est pas une primitive GitHub. Un dangling commit peut donc exister sur n’importe quelle plateforme git – Bitbucket, GitLab, GitHub, etc. Un dangling commit, c’est en fait, dans un dépôt de code donné, un arbre qui représente l’historique du projet, c’est-à-dire toutes les anciennes versions du code qui sont reliées entre elles ».
Un commit git capture un instantané de l’état d’un dépôt à un moment précis, y compris les modifications apportées au code et aux données. Chaque commit est identifié de manière unique par un hachage cryptographique. Si la suppression d’une branche, par exemple, supprime la référence à une chaîne de livraisons particulière, les livraisons elles-mêmes ne sont pas supprimées de la base de données d’objets du référentiel.
« Ces “dangling commits” sont comme une partie fondamentale documentée de git lui-même », a déclaré Ayrey, qui a expliqué que la façon dont les plateformes git traitent les “dangling commits” est une décision de la plateforme plutôt qu’une spécification de git.
Bitbucket, GitLab et GitHub, a déclaré Ayrey, ont ces commits même lorsque la connexion à l’arbre du code est rompue. Si vous avez l’identifiant pour y accéder directement, vous pouvez toujours télécharger les données associées.
Un problème largement connu
Selon Ayrey, ce problème est largement connu. Mais il existe un autre problème, lié aux forks (dépôts copiés), qui est plus spécifique à GitHub. Les forks, a-t-il expliqué, ne font pas partie des spécifications de Git, de sorte que chaque plateforme a sa propre implémentation. Ayrey a déclaré que pour GitHub, les commits en suspens peuvent être téléchargés via un fork si vous avez le hash d’identification, ou une partie de celui-ci.
« Si vous avez l’identifiant, vous pouvez les télécharger à partir du dépôt dans lequel ils ont été poussés à l’origine », a-t-il expliqué. « Il s’avère que vous pouvez également les télécharger à partir de n’importe quel fork de ce dépôt. Et cela fonctionne dans les deux sens. Ainsi, depuis le parent, vous pouvez télécharger ce commit dangling depuis le fork et depuis le fork, vous pouvez télécharger ce commit dangling depuis le parent ».
« Ce que nous avons découvert, c’est que même si vous supprimez le parent, et que le commit a été envoyé (push) vers le parent, ce dangling commit non seulement vit toujours, mais vous pouvez le télécharger à travers l’enfant, même s’il a été envoyé vers le parent, qu’il n’a jamais été tiré (pull) dans l’enfant, et que le parent a été supprimé, vous pouvez maintenant accéder à ce dangling commit. »
De plus, explique Ayrey, vous n’avez même pas besoin du hachage complet de l’identifiant pour accéder au commit. « Si vous connaissez les quatre premiers caractères de l’identifiant, GitHub complétera presque automatiquement le reste de l’identifiant pour vous », a-t-il déclaré, notant qu’avec seulement soixante-cinq mille combinaisons possibles pour ces caractères, il s’agit d’un nombre suffisamment restreint pour tester toutes les possibilités.
Quels risques cela représente ?
Interrogé sur les risques que cela présente, Ayrey a indiqué qu’il existe des archives d’événements GitHub qui enregistrent toutes les actions publiques de GitHub. De même que les archives de tweets de la Sunlight Foundation peuvent être utilisées pour étudier les déclarations publiques sur les médias sociaux, les archives d’événements de GitHub peuvent être utilisées pour des enquêtes judiciaires sur les activités des entreprises technologiques.
« Si [les entreprises technologiques] suppriment du code, si elles s’efforcent de supprimer quelque chose, cela ne veut pas toujours dire quelque chose », a-t-il expliqué. « Mais souvent, cela signifie quelque chose. Cela peut signifier qu’une clé ou un mot de passe [a été exposé]. Cela peut signifier qu’ils ont accidentellement mis en ligne un ensemble de données d’apprentissage automatique. Nous avons déjà vu cela. Ou cela peut signifier – et c’est rare – [que] l’attaquant a en fait backdoorisé son projet et qu’il en était un peu gêné… alors il a simplement supprimé la porte dérobée. »
À la question de savoir comment GitHub devrait réagir, Ayrey a répondu : « Si une plateforme crée une vulnérabilité, la documente et explique qu’il s’agit de quelque chose dont vous devriez être conscient et qui constitue un risque connu, est-ce que cela en fait moins une vulnérabilité ? »
source:developpez