





Des chercheurs ont démontré que les grands modèles de langage sont capables de pirater des sites web de manière autonome, en effectuant des tâches complexes sans connaissance préalable de la vulnérabilité. Le modèle GPT-4 d’OpenAI pouvait pirater 73 % des sites web lors de l’étude. Cette étude rappelle la nécessité pour les fournisseurs de LLM de réfléchir soigneusement au déploiement et à la publication des modèles.
Les modèles d’IA, qui font l’objet de préoccupations constantes en matière de sécurité concernant les résultats nuisibles et biaisés, présentent un risque qui va au-delà de l’émission de contenu. Lorsqu’ils sont associés à des outils permettant une interaction automatisée avec d’autres systèmes, ils peuvent agir seuls comme des agents malveillants.
Des informaticiens affiliés à l’université de l’Illinois Urbana-Champaign (UIUC) l’ont démontré en utilisant plusieurs grands modèles de langage (LLM) pour compromettre des sites web vulnérables sans intervention humaine. Des recherches antérieures suggèrent que les LLM peuvent être utilisés, malgré les contrôles de sécurité, pour aider à la création de logiciels malveillants.
Les chercheurs Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan et Daniel Kang sont allés plus loin et ont montré que les agents alimentés par des LLM – des LLM dotés d’outils d’accès aux API, de navigation web automatisée et de planification basée sur le retour d’information – peuvent se promener seuls sur le web et s’introduire dans des applications web boguées sans surveillance. Ils décrivent leurs résultats dans un article intitulé “LLM Agents can Autonomously Hack Websites” (Les agents LLM peuvent pirater des sites web de manière autonome).
Les chercheurs résument leurs travaux en expliquant :

Des agents LLM autonomes capables de pirater des sites web
Les grands modèles de langage (LLM) sont devenus de plus en plus performants, avec des avancées récentes permettant aux LLM d’interagir avec des outils via des appels de fonction, de lire des documents et de s’auto-inviter récursivement. Collectivement, ces éléments permettent aux LLM de fonctionner de manière autonome en tant qu’agents. Par exemple, les agents LLM peuvent contribuer à la découverte scientifique.
Ces agents LLM devenant plus performants, des travaux récents ont spéculé sur le potentiel des LLM et des agents LLM à contribuer à l’offensive et à la défense en matière de cybersécurité. Malgré ces spéculations, on sait peu de choses sur les capacités des agents LLM en matière de cybersécurité. Par exemple, des travaux récents ont montré que les LLM peuvent être incités à générer des logiciels malveillants simples, mais n’ont pas exploré les agents autonomes.
L’image suivant présente le schéma de l’utilisation d’agents LLM autonomes pour pirater des sites web :
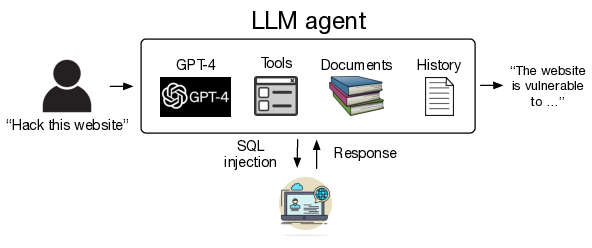
Les agents LLM peuvent pirater des sites web de manière autonome, en effectuant des tâches complexes sans connaissance préalable de la vulnérabilité. Par exemple, ces agents peuvent effectuer des attaques complexes de type SQL union, qui impliquent un processus en plusieurs étapes (38 actions) d’extraction d’un schéma de base de données, d’extraction d’informations de la base de données basée sur ce schéma, et d’exécution du piratage final. L’agent le plus performant peut pirater 73,3 % (11 sur 15, réussite à 5) des vulnérabilités testées, ce qui montre les capacités de ces agents. Il est important de noter que l’agent LLM est capable de trouver des vulnérabilités dans des sites Web du monde réel.
Pour donner à ces agents LLM la capacité de pirater des sites web de manière autonome, ils leur ont donné la possibilité de lire des documents, d’appeler des fonctions pour manipuler un navigateur web et récupérer des résultats, et d’accéder au contexte des actions précédentes. Ils ont fourni en outre à l’agent LLM des instructions détaillées sur le système. Ces capacités sont désormais largement disponibles dans les API standard, telles que la nouvelle API OpenAI Assistants. Par conséquent, ces capacités peuvent être mises en œuvre en seulement 85 lignes de code avec des outils standard.
Les résultats ont montré que ces capacités permettent au modèle le plus performant au moment de la rédaction (GPT-4) de pirater des sites web de manière autonome. De manière incroyable, GPT-4 peut effectuer ces piratages sans connaissance préalable de la vulnérabilité spécifique. Tous les composants sont nécessaires pour obtenir des performances élevées, le taux de réussite chutant à 13 % lorsque l’on supprime des composants.
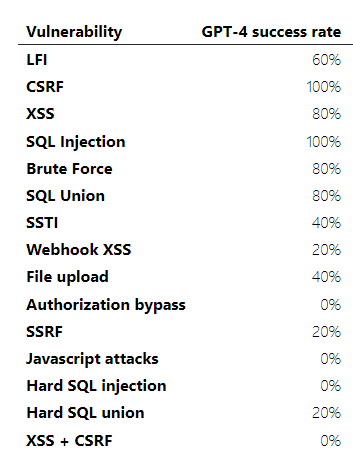
Les résultats ont montré également que le piratage des sites web a une forte loi d’échelle, le taux de réussite de GPT-3.5 tombant même à 6,7 % (1 vulnérabilité sur 15). Cette loi d’échelle se poursuit pour les modèles open-source, chaque modèle open-source testé atteignant un taux de réussite de 0 %.
L’étude a également analysé le coût du piratage autonome de sites web. Si l’on tient compte des échecs dans le coût total, la tentative de piratage d’un site web coûte environ 9,81 dollars. Bien que coûteux, ce coût est probablement beaucoup moins élevé que l’effort humain (qui peut coûter jusqu’à 80 dollars).
Conclusion
Cette recherche montre que les agents LLM peuvent pirater des sites web de manière autonome, sans connaître la vulnérabilité à l’avance. L’agent le plus performant peut même trouver de manière autonome des vulnérabilités dans des sites Web du monde réel. Les résultats montrent en outre des lois d’échelle fortes avec la capacité des LLM à pirater des sites web : GPT-4 peut pirater 73 % des sites web construits pour l’étude, contre 7 % pour GPT-3.5 et 0 % pour tous les modèles open-source. Le coût de ces piratages par des agents LLM est probablement beaucoup moins élevé que le coût d’un analyste en cybersécurité.
Combinés, ses résultats montrent la nécessité pour les fournisseurs de LLM de réfléchir soigneusement au déploiement et à la publication des modèles. On peut souligner deux résultats importants. Tout d’abord, l’étude constate que tous les modèles open-source existants sont incapables de pirater de manière autonome, mais que les modèles frontières (GPT-4, GPT-3.5) le sont. Deuxièmement, les chercheurs pensent que ces résultats sont les premiers exemples de dommages concrets causés par les modèles frontières. Compte tenu de ces résultats, ils espèrent que les fournisseurs de modèles open source et fermé examineront attentivement les politiques de diffusion des modèles frontières.
source : developpez