





Afin de produire des résultats qui seraient normalement filtrés et refusés
Microsoft a découvert une nouvelle méthode pour jailbreaker les outils d’intelligence artificielle (IA) de type grand modèle de langage (LLM). La méthode “Crescendo” se sert d’une série d’invites en apparence inoffensives pour produire un résultat qui serait normalement filtré et refusé. Microsoft partage également des méthodes de protection contre ce type d’attaque.
Un grand modèle de langage (LLM) est un modèle de langage remarquable pour sa capacité à réaliser une génération de langage à usage général et d’autres tâches de traitement du langage naturel telles que la classification. Les LLM acquièrent ces capacités en apprenant des relations statistiques à partir de documents textuels au cours d’un processus d’apprentissage auto-supervisé et semi-supervisé à forte intensité de calcul. Les LLM peuvent être utilisés pour la génération de texte, une forme d’IA générative, en prenant un texte en entrée et en prédisant de manière répétée le prochain mot ou token.
Microsoft a découvert une nouvelle méthode pour jailbreaker les outils d’intelligence artificielle (IA) de type grand modèle de langage (LLM) et a fait part de ses efforts continus pour améliorer la sûreté et la sécurité des LLM. Microsoft a révélé pour la première fois la méthode de piratage “Crescendo” du LLM dans un article publié le 2 avril, qui décrit comment un pirate peut envoyer une série d’invites apparemment anodines pour amener progressivement un chatbot, tel que ChatGPT d’OpenAI, Gemini de Google, LlaMA de Meta ou Claude d’Anthropic, à produire un résultat qui serait normalement filtré et refusé par le modèle LLM. Par exemple, au lieu de demander au chatbot comment fabriquer un cocktail Molotov, l’attaquant pourrait d’abord poser des questions sur l’histoire des cocktails Molotov, puis, en se référant aux résultats précédents du LLM, enchaîner avec des questions sur la façon dont ils ont été fabriqués dans le passé.
Les chercheurs de Microsoft ont indiqué qu’une attaque réussie pouvait généralement être réalisée en une chaîne de moins de 10 tours d’interaction et que certaines versions de l’attaque avaient un taux de réussite de 100 % par rapport aux modèles testés. Par exemple, lorsque l’attaque est automatisée à l’aide d’une méthode que les chercheurs ont appelée “Crescendomation”, qui s’appuie sur un autre LLM pour générer et affiner les invites de jailbreak, elle a atteint un taux de réussite de 100 % en convainquant GPT-3.5, GPT-4, Gemini-Pro et LLaMA-2 70b de produire des informations erronées liées aux élections et des diatribes contenant des blasphèmes. Microsoft a signalé les vulnérabilités de Crescendo aux fournisseurs de LLM concernés et a expliqué comment il a amélioré ses défenses LLM contre Crescendo et d’autres attaques en utilisant de nouveaux outils, notamment ses fonctions “AI Watchdog” et “AI Spotlight“.
Comment Microsoft découvre et atténue les attaques évolutives contre les garde-fous de l’IA ?

Potentiel de manipulation malveillante des LLM
L’une des principales préoccupations liées à l’IA est son utilisation potentielle à des fins malveillantes. Pour éviter cela, les systèmes d’IA de Microsoft sont construits avec plusieurs couches de défenses dans leur architecture. L’un des objectifs de ces défenses est de limiter les actions du LLM, afin de s’aligner sur les valeurs et les objectifs humains des développeurs.
Mais il arrive que des acteurs malveillants tentent de contourner ces protections dans le but de réaliser des actions non autorisées, ce qui peut donner lieu à ce que l’on appelle un “jailbreak”. Les conséquences peuvent aller d’actions non approuvées mais moins nocives – comme faire parler l’interface de l’IA comme un pirate – à des actions très graves, comme inciter l’IA à fournir des instructions détaillées sur la manière de réaliser des activités illégales. C’est pourquoi de nombreux efforts sont déployés pour renforcer les défenses des jailbreaks afin de protéger les applications intégrées à l’IA contre ces comportements.
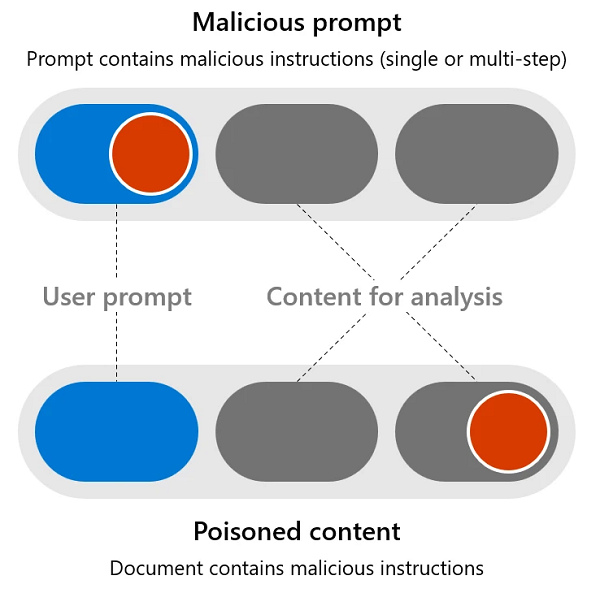
Si les applications intégrées à l’IA peuvent être attaquées comme des logiciels traditionnels (avec des méthodes telles que les débordements de mémoire tampon et les scripts intersites), elles peuvent également être vulnérables à des attaques plus spécialisées qui exploitent leurs caractéristiques uniques, notamment la manipulation ou l’injection d’instructions malveillantes en s’adressant au modèle d’IA par l’intermédiaire de l’invite de l’utilisateur. On peut répartir ces risques en deux groupes de techniques d’attaque :
- Invitations malveillantes : Lorsque l’utilisateur tente de contourner les systèmes de sécurité afin d’atteindre un objectif dangereux. On parle également d’attaque par injection d’invite utilisateur/directe ou UPIA.
- Contenu empoisonné : Lorsqu’un utilisateur bien intentionné demande au système d’IA de traiter un document apparemment inoffensif (comme le résumé d’un courriel) qui contient un contenu créé par un tiers malveillant dans le but d’exploiter une faille du système d’IA. Également connue sous le nom d’attaque par injection croisée/indirecte, ou XPIA.
Microsoft partage deux des avancées de son équipe dans ce domaine : la découverte d’une technique puissante pour neutraliser le contenu empoisonné, et la découverte d’une nouvelle famille d’attaques promptes malveillantes, et comment se défendre contre elles avec plusieurs couches d’atténuation.
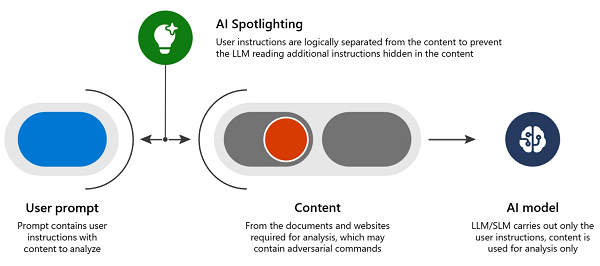
Neutralisation du contenu empoisonné (Spotlighting)
Les attaques par injection d’invites par le biais de contenus empoisonnés constituent un risque majeur pour la sécurité, car un attaquant qui procède ainsi peut potentiellement donner des ordres au système d’IA comme s’il était l’utilisateur. Par exemple, un courriel malveillant pourrait contenir une charge utile qui, une fois résumée, amènerait le système à rechercher dans la messagerie de l’utilisateur (à l’aide de ses informations d’identification) d’autres courriels portant sur des sujets sensibles – par exemple, “Réinitialisation du mot de passe” – et à exfiltrer le contenu de ces courriels vers l’attaquant en récupérant une image à partir d’une URL contrôlée par l’attaquant. De telles capacités présentant un intérêt évident pour un large éventail d’adversaires, il est essentiel de s’en protéger pour que tout service d’IA puisse fonctionner en toute sécurité.

Spotlighting (également connu sous le nom de marquage de données) pour rendre les données externes clairement séparables des instructions par le LLM, avec différentes méthodes de marquage offrant une gamme de compromis de qualité et de robustesse qui dépendent du modèle utilisé.
Atténuer le risque de menaces multitours (Crescendo)

Au fond, Crescendo incite les LLM à générer des contenus malveillants en exploitant leurs propres réponses. En posant des questions ou des invites soigneusement conçues qui conduisent progressivement le LLM vers un résultat souhaité, plutôt que de lui demander l’objectif en une seule fois, il est possible de contourner les garde-fous et les filtres, ce qui peut généralement être réalisé en moins de 10 tours d’interaction.
Bien que les attaques de Crescendo aient été une découverte surprenante, il est important de noter que ces attaques ne constituent pas une menace directe pour la vie privée des utilisateurs qui interagissent avec le système d’IA ciblé par Crescendo, ni pour la sécurité du système d’IA lui-même. Ce que les attaques de Crescendo contournent et mettent en échec, c’est le filtrage de contenu qui régule le LLM et qui permet d’empêcher une interface d’IA de se comporter de manière indésirable.
Microsoft s’engage à rechercher et à traiter en permanence ces types d’attaques, ainsi que d’autres, afin de contribuer à maintenir la sécurité du fonctionnement et des performances des systèmes d’IA pour tous. Dans le cas de Crescendo, ils ont effectué des mises à jour logicielles de la technologie LLM qui sous-tend les offres d’IA de Microsoft, y compris les assistants d’IA Copilot, afin d’atténuer l’impact de ce contournement du garde-fou de l’IA à plusieurs tours.

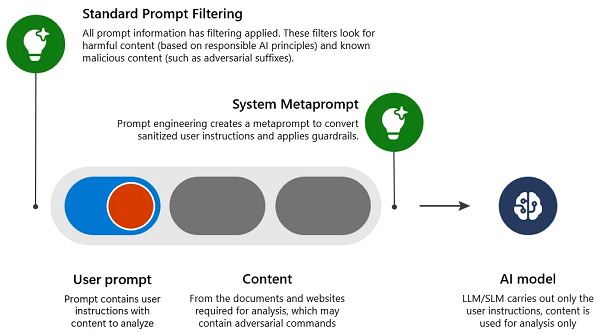
Pour comprendre comment Microsoft a résolu le problème, il faut examiner comment ils ont atténué une attaque par invite malveillante standard (étape unique, également connue sous le nom de “one-shot jailbreak”) :
- Filtrage de l’invite standard : Détecter et rejeter les entrées qui contiennent des intentions nuisibles ou malveillantes, susceptibles de contourner les garde-fous (provoquant une attaque de type jailbreak).
- Métaprompte du système : Ingénierie d’invite dans le système pour expliquer clairement au LLM comment se comporter et fournir des garde-fous supplémentaires.

En outre, le LLM lui-même ne voit rien qui sorte de l’ordinaire, puisque chaque étape successive est bien ancrée dans ce qu’elle a généré à l’étape précédente, avec juste une petite demande supplémentaire ; cela élimine bon nombre des signaux les plus importants qui normalement seraient utilisés pour prévenir ce type d’attaque.
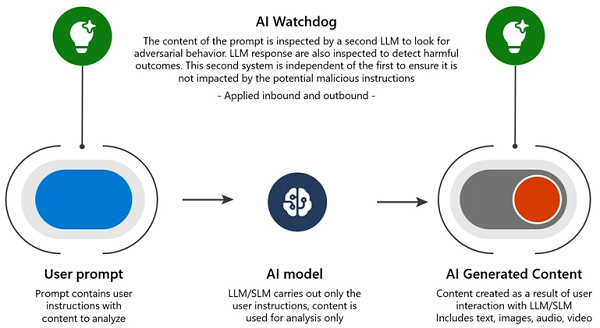
Pour résoudre les problèmes uniques des jailbreaks LLM multitours, Microsoft a créé des couches supplémentaires d’atténuation en plus des précédentes mentionnées ci-dessus :
- Filtre d’invite multitours : Ils ont adapté les filtres d’entrée pour qu’ils tiennent compte de l’ensemble de la conversation précédente, et pas seulement de l’interaction immédiate. Ils ont constaté que le fait de transmettre cette fenêtre contextuelle plus large aux détecteurs d’intentions malveillantes existants, sans améliorer les détecteurs du tout, réduisait de manière significative l’efficacité de Crescendo.
- AI Watchdog : Déploiement d’un système de détection piloté par l’IA et entraîné sur des exemples contradictoires, comme un chien renifleur à l’aéroport à la recherche d’articles de contrebande dans les bagages. En tant que système d’IA distinct, il évite d’être influencé par des instructions malveillantes. Microsoft Azure AI Content Safety est un exemple de cette approche.
- Recherche avancée : Microsoft investit dans la recherche de mesures d’atténuation plus complexes, issues d’une meilleure compréhension de la manière dont les LLM traitent les demandes et s’égarent. Ces mesures peuvent protéger non seulement contre Crescendo, mais aussi contre la grande famille des attaques d’ingénierie sociale contre les LLM.
Microsoft aide à protéger les systèmes d’IA
L’IA a le potentiel d’apporter de nombreux avantages à nos vies. Mais il est important d’être conscient des nouveaux vecteurs d’attaque et de prendre des mesures pour y remédier. En travaillant ensemble et en partageant les découvertes de vulnérabilités, on peut continuer à améliorer la sûreté et la sécurité des systèmes d’IA. Avec les bonnes protections de produits en place, on peut être prudemment optimistes quant à l’avenir de l’IA générative, et à embrasser les possibilités en toute sécurité, avec confiance.
Pour permettre aux professionnels de la sécurité et aux ingénieurs en apprentissage automatique de détecter de manière proactive les risques dans leurs propres systèmes d’IA générative, Microsoft a publié un cadre d’automatisation ouvert, PyRIT (Python Risk Identification Toolkit for generative AI).
Si vous découvrez de nouvelles vulnérabilités dans une plateforme d’IA, Microsoft vous encourage à suivre les pratiques de divulgation responsable du propriétaire de la plateforme.
source : developpez