





Y compris les émotions et le ton d’un orateur
Microsoft a récemment publié VALL-E, un nouveau modèle de langage pour la synthèse vocale TTS (text-to-speech). Après avoir été formé sur 60 000 heures de données vocales en anglais, il a démontré des capacités d’apprentissage en contexte dans des situations sans coup sûr. VALL-E vous permet de créer un discours personnalisé de haute qualité avec seulement un enregistrement de 3 secondes. Il permet des techniques TTS basées sur des invites qui sont instantanées et contextuelles. Il n’est pas nécessaire d’ajouter une ingénierie structurelle ou des caractéristiques acoustiques préconçues.
Il s’agit d’un progrès significatif dans la direction de systèmes TTS au son plus naturel. Microsoft a fourni quelques exemples du modèle utilisé qui montre les évolutions dans le développement de la technologie TTS.
Microsoft a récemment publié un outil d’intelligence artificielle connu sous le nom de VALL-E qui peut reproduire la voix des gens. L’outil a été formé sur 60 000 heures de données vocales en anglais et utilise des clips de 3 secondes de voix spécifiques pour générer du contenu. Contrairement à de nombreux outils d’intelligence artificielle, VALL-E peut reproduire les émotions et le ton d’un orateur, même lors de la création d’un enregistrement de mots que l’orateur d’origine n’a jamais prononcés. En clair, une fois qu’il a appris une voix spécifique, VALL-E peut synthétiser l’audio de cette personne disant n’importe quoi et le faire d’une manière qui tente de préserver le ton émotionnel de l’orateur.
En plus de préserver le timbre vocal et le ton émotionnel d’un locuteur, VALL-E peut également imiter « l’environnement acoustique » de l’échantillon audio. Par exemple, si l’échantillon provient d’un appel téléphonique, la sortie audio ressemblera également à un appel téléphonique.
Un article de l’Université Cornell a utilisé VALL-E pour synthétiser plusieurs voix. Quelques exemples de travaux sont disponibles sur GitHub.
Les échantillons de voix partagés par Microsoft varient en qualité. Alors que certains d’entre eux semblent naturels, d’autres sont clairement générés par des machines et semblent robotiques. Bien sûr, l’IA a tendance à s’améliorer avec le temps, donc à l’avenir, les enregistrements générés seront probablement plus convaincants. De plus, VALL-E n’utilise que des enregistrements de 3 secondes comme invite. Si la technologie était utilisée avec un ensemble d’échantillons plus grand, elle pourrait sans aucun doute créer des échantillons plus réalistes.
Ses créateurs pensent que VALL-E pourrait être utilisé pour des applications de synthèse vocale de haute qualité, l’édition de la parole où un enregistrement d’une personne pourrait être édité et modifié à partir d’une transcription textuelle.
VALL-E est un « modèle de langage de codec neuronal » qui s’appuie sur une technologie baptisée EnCodec, qui a été présentée par Meta en octobre 2022. Encodec est une méthode de compression audio alimentée par l’IA, qui serait capable de compresser le son 10 fois plus petit que le format MP3 à 64 kbps, sans perte de qualité. Selon Meta, cette technique pourrait améliorer considérablement la qualité sonore des discours sur les connexions à faible bande passante, comme les appels téléphoniques dans les zones où le service est irrégulier. Les chercheurs de Meta auraient obtenu des résultats de pointe en matière de compression audio vocale à faible débit (1,5 kbps à 12 kbps), évalués par des annotateurs humains qui ont comparé plusieurs méthodes de compression, dont le dernier codec Lyra-v2 de Google, avec la méthode non compressée et les ont classées en conséquence.
Contrairement à d’autres méthodes de synthèse vocale qui synthétisent généralement la parole en manipulant des formes d’onde, VALL-E génère des codes de codec audio discrets à partir d’invites textuelles et acoustiques. Il analyse essentiellement le son d’une personne, décompose ces informations en composants discrets (appelés « jetons ») grâce à EnCodec, et utilise des données d’entraînement pour faire correspondre ce qu’il « sait » sur la façon dont cette voix sonnerait si elle prononçait d’autres phrases en dehors de l’échantillon.
Microsoft
Nous introduisons une approche de modélisation du langage pour la synthèse vocale (TTS). Plus précisément, nous entraînons un modèle de langage de codec neuronal (appelé VALL-E) à l'aide de codes discrets dérivés d'un modèle de codec audio neuronal prêt à l'emploi, et considérons TTS comme une tâche de modélisation de langage conditionnelle plutôt qu'une régression continue du signal comme dans les travaux précédents. Au cours de la phase de pré-formation, nous augmentons les données de formation TTS à 60 000 heures de conversation en anglais, ce qui est des centaines de fois plus important que les systèmes existants. VALL-E émerge des capacités d'apprentissage en contexte et peut être utilisé pour synthétiser un discours personnalisé de haute qualité avec seulement un enregistrement inscrit de 3 secondes d'un locuteur invisible comme invite acoustique. Les résultats des expériences montrent que VALL-E surpasse de manière significative le système TTS zéro-shot de pointe en termes de naturel de la parole et de similarité des locuteurs. De plus, nous constatons que VALL-E pourrait préserver l'émotion de l'orateur et l'environnement acoustique de l'invite acoustique en synthèse.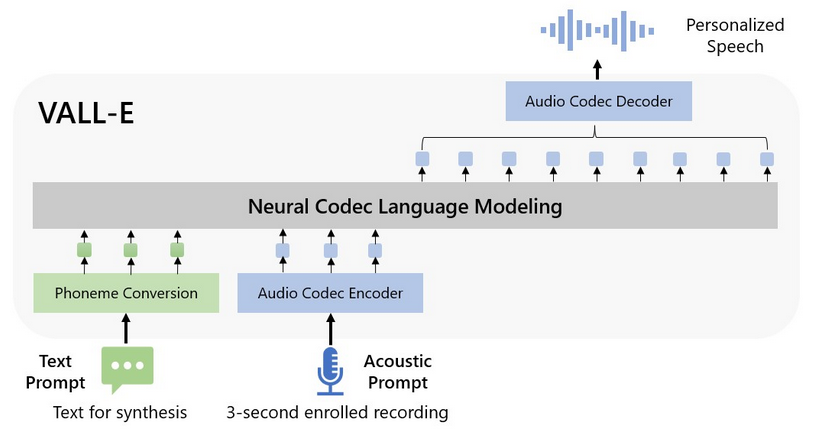
Déjà des préoccupations éthiques
Pour le moment, VALL-E n’est généralement pas disponible, ce qui peut être une bonne chose car les répliques de la voix des personnes générées par l’IA pourraient être utilisées de manière dangereuse par des acteurs malveillants et d’autres personnes ayant des intentions malveillantes :
« Étant donné que VALL-E pourrait synthétiser la parole qui maintient l’identité du locuteur, il peut comporter des risques potentiels d’utilisation abusive du modèle, tels que l’usurpation d’identification vocale ou l’usurpation d’identité d’un locuteur spécifique. Pour atténuer ces risques, il est possible de construire un modèle de détection pour discriminer si un clip audio a été synthétisé par VALL-E. Nous mettrons également en pratique les principes de Microsoft AI lors du développement ultérieur des modèles ».
Bien que VALL-E soit sans aucun doute impressionnant, il soulève plusieurs préoccupations éthiques. À mesure que l’intelligence artificielle deviendra plus puissante, les voix générées par VALL-E et les technologies similaires deviendront plus convaincantes. Cela ouvrirait la porte à des appels de spam réalistes reproduisant les voix de personnes réelles qu’une victime potentielle connaît.
Les politiciens et autres personnalités publiques pourraient également être usurpés. Avec la vitesse de propagation des médias sociaux et la polarité des discussions politiques, il est peu probable que beaucoup s’arrêtent pour demander si un enregistrement scandaleux est authentique, tant qu’il semble au moins quelque peu authentique.
Les problèmes de sécurité viennent également à l’esprit. Certaines banques ont une option visant à utiliser la voix comme mot de passe lorsqu’un propriétaire de compte appelle. Il existe des mesures en place pour détecter les enregistrements vocaux et nous pouvons supposer que la technologie pourrait détecter si une voix VALL-E était utilisée. Cela étant dit, il y a de quoi rendre mal à l’aise. Il y a de fortes chances que la course aux armements s’intensifie entre le contenu généré par l’IA et les logiciels de détection de l’IA.
Bien qu’il ne s’agisse pas d’un problème de sécurité, certains ont évoqué le fait que les acteurs faisant des doublages pourraient perdre du travail au profit de VALL-E et des technologies concurrentes. Bien qu’il soit malheureux de voir des gens perdre leur travail, difficile de voir comment contourner cela. Si VALL-E atteint un point où il peut remplacer les acteurs vocaux pour les livres audio ou d’autres contenus, les entreprises vont l’utiliser. C’est juste la réalité de la technologie qui progresse.
En fait, Apple a récemment annoncé une fonctionnalité qui utilise l’IA pour lire des livres audio. « De plus en plus d’amateurs de livres écoutent des livres audio, mais seule une fraction des livres est convertie en audio, laissant des millions de titres inédits », a déclaré Apple dans un article de blog. « De nombreux auteurs – en particulier les auteurs indépendants et ceux associés à de petits éditeurs – ne sont pas en mesure de créer des livres audio en raison du coût et de la complexité de la production. La narration numérique Apple Books rend la création de livres audio plus accessible à tous, vous aidant à répondre à la demande croissante. en mettant plus de livres à la disposition des auditeurs ».
La nouvelle fonctionnalité permettra aux auteurs auto-publiés d’élargir leur audience et leur donnera une autre source de revenus. Comme toujours, Apple prendra jusqu’à 30% de tous les achats effectués sur les applications disponibles sur son App Store.
Comme toute technologie, VALL-E sera utilisé pour le bien, le mal et tout le reste. Microsoft a une déclaration d’éthique sur l’utilisation de VALL-E, mais l’avenir de son utilisation est encore trouble. Le président de Microsoft, Brad Smith, a discuté de la réglementation de l’IA dans le passé. Nous devrons voir quelles mesures Microsoft met en place pour réglementer l’utilisation de VALL-E.
source : developpez